Consistent hashing
Before you jump into consistent hashing…
- Consistent hashing is NOT the silver bullet to all problems. It has trade-offs based on the data distribution, queries, and hotkeys.
Why?
- assuming a load balancer where it uses modulo operation to distribute the requests to X servers.
- When one server is down, and we have to redistribute the request to the remaining X - 1 servers, almost all the requests would have mapped to a different server compared to original setup.
Consistent hashing is a special kind of hashing such that when a hash table is re-sized and consistent hashing is used, only k/n keys need to be remapped on average, where k is the number of keys, and n is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped - from wiki
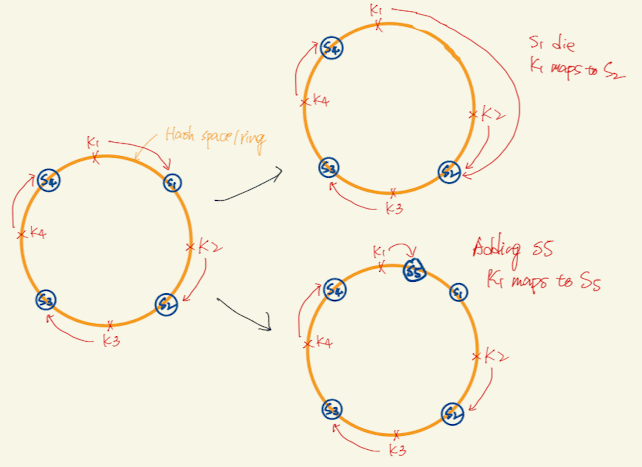
- So it minimize data migration due to shard redistribution when servers are added, removed, and down.
How? (Basics)
- cache keys are hashed onto the hash “ring” (ring-like hash space), instead of the modulo operation
- Each server is mapped to certain point on the ring as well.
- To determine which server a key is stored on, we go clockwise from the key position on the ring until a server is found.
- As a result, adding a new server or delete a new server should only change partial portion
Basic is alright but …
- it is impossible to keep the same size of partitions on the ring for all servers considering a server can be added or removed. A partition is the hash space between adjacent servers. It is possible that the size of the partitions on the ring assigned to each server is very small or fairly large.
- it is possible to have a non-uniform key distribution on the ring.
Solution
- basically separate the ring to granular parts through introducing virtual nodes
- Each virtual node refers to one real node, and each server is represented by multiple virtual nodes on the ring.
- As the number of virtual nodes increases, the distribution of keys becomes more balanced. This is because the standard deviation gets smaller with more virtual nodes, leading to balanced data distribution.
- More spaces are needed for the virtual nodes. This is a tradeoff, and we can tune the number of virtual nodes to fit our system requirements.
What
- Distribute data across multiple servers evenly.
- Minimize data movement when nodes are added or removed.
- Heterogeneity: the number of virtual nodes for a server is proportional to the server capacity. For example, servers with higher capacity are assigned with more virtual nodes.
Last updated on